
Rendering Bidirectional Text with multiple fonts and styles in an immediate mode GUI
The sorely missing out-of-the-box feature in all IMGUI libraries
There are several IMGUI libraries out there, some in C, some in other languages, but they all seem to be missing a cruicial feature that makes them a no-go for me and many others: they only support latin text, and even when they do support other languages, it’s only languages with a simple script, and you’re restricted to a single font per text block.
This means IMGUI is effectively unusable except for tools where you expect that over 99% of the text is latin; but otherwise, anyone who wants to create a serious cross-platform application with a graphical interface is still basically forced to use something that is based on an embedded web browser, thus contributing to the problem of slow and bloated software that frustrates users and shorten mobile phone batteries’ life spans, among other problems.1
So I’ve been working on a solution. Here’s what I have so far:

And here’s a little video so you can see that we can resize, change alignment, and perform selections and editing:
It wasn’t exactly “trivial” but it wasn’t difficult either. The heavy lifting was already done by Behdad Esfahbod, Benoit KUGLER, Elias Naur, and others.
Loading Font Data: github.com/benoitkugler/textlayout/fonts/truetype
Rendering 2D paths (for rendering glyphs): Gioui Drawing Primitives
Glyph Positioning: HarfBuzz Go port at: github.com/benoitkugler/textlayout/harfbuzz
Bidi Algorithm implementation: golang.org/x/text/unicode/bidi
Simple LRU Cache: github.com/dboslee/lru
In a sense what I did is just glue programming! I’m just putting things together that were written by other people and would have been non-trivial for me to reimplement from scratch; at least in a short amount of time.2
What it takes to display bidirectional text with complex scripts
Before even getting into having multiple style spans, let’s just focus on plain text rendering with support for multiple languages, complex script, and bidirectionality.
Immediately we face all of the following problems at the same time:3
How to render individual glyphs
Given a specific (x, y) point on the screen, a font, and a code point (rune): how do you make the glyph show up on the screen? Luckily the libraries already solve the hard parts of this problem for us: Loading glyph data and rendering 2D shapes on the screen.
How to position glyphs relative to each other
This is what HarfBuzz solves for us.
For Latin text this problem is trivial: move the cursor by the glyph’s XAdvance and ask the font if there’s any kerning between the current rune and the previous rune: the kerning itself is just another XOffset to be applied on top of the XAdvance.
For other languages, specially Arabic, things are more involved. You need some knowledge about the language, and you need to ask the font how to place special characters (like diacritical marks) on the previous glyphs.
But HarfBuzz operates on a segment of text, not the whole text. So you need to break up the text into segments that have a set of properties in common: same script, same directionality, same font.
For reference, see What HarfBuzz doesn't do.
How to decide when to move to the next line
A simple/naive approach is to just use ‘spaces’ as potential break points and precompute how much space each word takes, and move to a new line as soon as you find a word that would overflow the current line.
The basic idea works, but we need to modify it a little so that we’re not considering words per se, but individually breakable segments of text. This is because the potential breakpoints are not just spaces. Eash Asian languages (Japanese, Korea, Chinese) do not generally use spaces to separate between words; so you can break the line on any character within the text. On the other hand, there are other characters that might come into consideration, like parenthesis and other symbols.
It’s a kind of a hairy problem, but there’s a heuristic that everyone seems to be using and is specified by the unicode consortium. I have no idea if it’s any good, but we will be using it, at least as our starting point. If we find flaws with it, we’ll see if we can make improvements, but that’s for another day.
The idea is simple: analyze the flow of text to give each rune index one of three breakability classes: “Must Break”, “May Break”, and “No Break”.
The part where we analyze the flow of text is the “hairy” bit in that it’s a combination of several heuristics, but like I said we’re just following the unicode docs blindly for now, so actually implementing it is mostly mechanical.
How to support bidirectional text
Again the unicode consortium publishes a document specifying how to do it. I haven’t read it carefully so I just use the implementation provided by the package under golang.org/x.
How to support font fallback
It comes down to “breaking” the segment (during the segmentation process) if we find a rune that is not supported by the current font.
If we do solve all of the above, then adding multiple fonts/sizes/colors becomes relatively easy: it’s just aother thing to consider when segmenting the text.
Segmentation and Line Breaking
The most significant part of our code (other than the glueing) is segmentation. If we have segments, everything is trivial:
Shaping: just pass the segments to harfbuzz one by one and store the result
Line wrapping/breaking: cumilitavely measure the width of consecutive segments until they exceed the line width, and when that happens, backtrack to the last segment that started on a breakable index and break there.4
Batching/Caching: we can treat segments as the smallest resuable unit in the rendering pipeline. If we know we’ve seen this segment and have rendered it before, we don’t need to do it again.
Multiple fonts/sizes/colors: everything in the segment uses the same font, same size, same color, so when rendering a segment we don’t need to worry about any of this changing.
Segmentation itself is not that difficult either: we just need to know for each rune index what is the script, direction, breakability, font, size, color, etc is. Iterate on the runes indecies and compare these properties; once any of them changes, break the segment (for breakability class, we break the segment when we find any rune that has “Must Break” or “May Break” class).
Now, our concept of a segment possibly confabulates a few separate concerns:
The segment of text to pass to harfbuzz for shaping
The segment of text that can be rendered using the same font/color/size
The segment of text that can be used for line breaking
Points 2 and 3 are actually tightly coupled: if you’re going to render the text in segments, you need each segment to be on the same line to keep the process simple. For point 1 (Shaping) it’s a bit of an open question for me but I’m leaning on “it’s not a problem”: does it make sense to shape text at line boundaries? I’m not sure it does. At least for Arabic it doesn’t make sense. So I think it’s perfectly fine that the concept of a segment covers all three of these concepts.
HarfBuzz
Given a segment of text and a font, HarfBuzz will give you back a list of glyph ids and their placement. To render the segment, you iterate over the glyph ids one by one, fetch the glyph from the font, render it with the positioning in mind, then move the cursor horizontally by the given XAdvance, and repeat until you render all the characters in the segment.
There are a few caveats worth keeping in mind: not all runes will have a corresponding glyph id: it could be that several runes contribute to just one glyph id, on the other hand, some runes might have no matching glyph at all. These caveats don’t affect the rendering of text, but they will come into play when we want to support selection and keyboard cursor movement.
Bidirectionality
The first thing we need to do is to assign an R or L direction to every individual rune in the input string. Many runes have an intrinsic directionality to them: they are either a part of an RTL script or an LTR script. But some runes don’t, and whether they end up as part of an RTL segment or an LTR segment depends on the context. This is what the bidi algorithm is for, and is what the bidi package from golang.org/x does for us.
The next step is changing up the order of how glyphs are displayed depending on directionality. Assuming we’re always rendering from left to right, all the RTL segments need to be “reversed”. This is actually surprisingly simple to apply, because you don’t need to worry much about context here; you do it on a line-by-line basis, and it doesn’t matter what’s on the previous or next line.
Once line break points are determined, all we have to do is to “reverse” the sequence of R glyphs if the paragraph base direction is LTR. If the base direction is RTL, then we reverse the entire line then reverse consecutive sequences of L glyphs.
In our case, we don’t deal directly with individual glyphs but with segments. HarfBuzz helps us a little bit by automatically reversin the glyph order of RTL segments. So what we have to do is find consecutive segments whose direction is the opposite of the base direction, and reverse them.
We don’t actually want to “reverse” the order of segments; we want to keep the segments intact so we can cache and reuse them for rendering later frames; we don’t want a resizing of the window (or the text box) to force us to recompute the segments and reshape them.
Instead each line will have a list of segment indecies (as numbers), and we apply the reversals on that list.
There’s a slight complication regarding the placement of spaces, but it’s solved easily by making spaces their own segment. So in addition to all the properties we use to break segments, we also use the property of weather the runes in the segment are all spaces or are all non-spaces.
I made a simple illustration hoping that a visualization helps clarify the point.
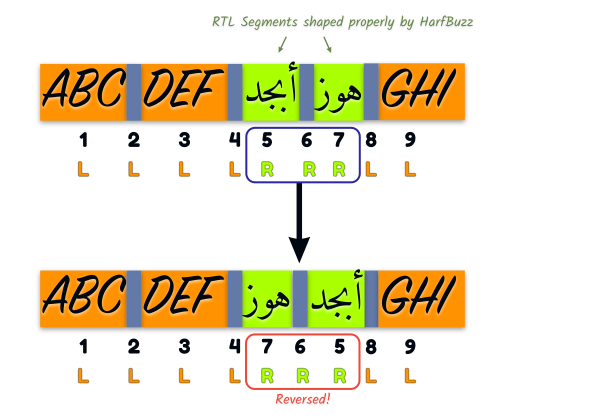
We have a line of text broken up into 9 segments. Segments 5 to 7 (inclusive) are all R segments within an LTR line, so we need to reverse them.
Note that each individual segment is shaped correctly by HarfBuzz, and the glyphs within the segment are layed out such that if we start rendering them from left to right, we get the correct result. But this is not enough for correctly displaying the line as a whole: we need the whole section of R segments to be reversed.
Glyph Rendering
This whole experiment is being done within the context of gioui5 immediate mode library, but unfortunately their text package is a bit high level, and the abstraction it works with doesn’t lend itself to the kind of tasks we need to do. So instead, we load the glyphs from the fonts directly and draw them using the shape drawing primitives provided by gioui.
Glyphs specified by fonts are basically segments of a path. Each segment is either a line, a quadratic bezier curve, or a cubic bezier curve. Gioui provides utilities for drawing these on the GPU. I don’t exactly know how it works, but I assume it sends the point data to the GPU as a vertex buffer and uses a shader to fill/stroke the resulting path.
The extra nice bit that gioui provides is the ability to create a “macro” and cache it for later. So if we have a macro to render a specific glyph, we don’t have to specify the path/shape every single frame; we can just reuse the macro. I think this reuses the vertex buffer on the GPU, but I have no evidence either way.
Caching intermediate computations
We are working in Go, where the compiler does not really optimize much, and the memory management is automatic/GC based, so we can’t use arena allocator to optimize memory access. Instead we just use the builtin slice type.6
The code I’m writing is not optimized either. I just wrote the code in a straight forward manner that seems non-pessemized to me. It’s very possible that I’m doing a lot of things in a very suboptimal way.
Before I introduced caching, rendering a small text box took about 1ms ~ 3ms on my Apple M2 Macbook Air, and about 5ms when the debugger was attached. This is generally considered slow. If the screen has 4 or 5 text boxes that would come close to taking up 16ms (a whole frame for a 60fps application)7 and leave no time for the application to do anything meaningful, not to mention other things on the UI.
Luckily we don’t need to go through any heroic efforts to make things better. As Casey Muratori has demonstrated to all of us during the refterm saga, a little caching goes a long way.8
By caching many of the intermediate computations, the rendering time (other than the first time) went down to about 5µs (microseconds). That is over 200x faster.
Now, the way I did caching is probably not great: I’m using the hash as the key in the LRU cache. The key is 64bits so there’s potential chance of collision. I haven’t done the calculations to prove (or disprove) that this case is statistically negligible. We might have to do a bit more to prevent collisions, but for now this should suffice.
I’m caching the following computations:
Text Bidi (whole paragraph)
Text Breakability class (whole paragraph)
Segmentation (whole paragraph)
Line breaks (whole paragraph)
HarfBuzz shaping (per segment)
Does Font have Glyph?
Font Glyph Outline
Gio macro to render a segment
Gio macro to render text (whole paragraph)
If the text does not change from frame to frame, there’s almost nothing to compute: just get things from the cache.
If the text is resized, we have to recompute the line breaks and rebuild the macro to render the paragraph, but the segments (and the macros that render them) are reused. During resize, time to render a block of text jumps from 5µs to the 40µs~80µs range.
Other topics
There are a few other topics probably worth discussin which this article does not cover:
Paragraph alignment (left/right/center/just).
Supporting multiple style spans (with different color, font family, size)
Rendering text selection highlights (necessary to make the text feel “alive” by responding to users mouse click + drag interaction)
Editing text without screwing up the style spans
These topics (and potentially others) will be covered (inshallah) in later posts.
The code
The whole project is done in the spirit of experimentation. The API is not particularly polished, and there’s hardly any documentation or testing code.
I’m sharing it for reference, but please do NOT import it as a dependency in your project!
If you would like to use the code, COPY it into your own repository. Don’t say you copied the code from me: take FULL responsibility for it; treat it as YOUR code! I’m not responsible for what happens. If you do want to give credit (completely optional; you absolutely don’t have to), you may link to this post.
With that said, here’s it is: The Code on Source Hut
The latest commit at the time of this writing is f9097ced
Now, the plan is to develop this further and stabilize it, because there are a few real applications I want to build on top of this. But for now treat it as an experimental / preview tech.
The code for setting up the title block in the above screenshot looks like this:
// global default text style
var textStyle = DefaultTextStyle()
textStyle.SetFamily(NOTO_SANS, NOTO_NASKH, NOTO_SANS_JP, NOTO_SANS_SC)
size := unit.Sp(20)
var style = textStyle
style.Size = size
var label = "Bidirectional, Rich, MultiFont, Complex Text Layout مع بعض العربي 日本語も出来る!"
DEBUGStyleSubstring(label, "Rich", &style, func(f *FontStyle) {
f.FirstFamily("Noto Serif")
f.Color = Green
f.Weight = WeightBold
f.Slope = SlopeItalic
f.Size *= 1.3
})
DEBUGStyleSubstring(label, "Multi", &style, func(f *FontStyle) {
f.FirstFamily("Caveat")
f.Size *= 1.4
})
DEBUGStyleSubstring(label, "Font", &style, func(f *FontStyle) {
f.FirstFamily("Great Vibes")
f.Size *= 1.5
})
DEBUGStyleSubstring(label, "العربي", &style, func(f *FontStyle) {
f.FirstFamily("Noto Kufi Arabic")
f.Color = Blue
f.Weight = WeightBold
})
DEBUGStyleSubstring(label, "日本語", &style, func(f *FontStyle) {
f.FirstFamily("AiharaHudemojiKaisho")
f.Color = Red
f.Size *= 1.5
})
uiState.TitleLabel = MakeTextWidget(label, style)
uiState.TitleLabel.Editable = trueAnd for rendering it we do this:
// gtx is a rendering context
// rect is a rectangle
DrawText(gtx, rect, &uiState.TitleLabel)Happy Hacking
Obviously I’m talking about “Electron” and similar tech. Now, another option in this space is “Flutter”, (which does not embed Chrome, though it uses the same underlying library (Skia) for rendering graphics and text), but the verdict seems to be that it’s slow anyway, so it’s not really a very good option.
The bidi algorithm is probably easy to implement from scratch since the specification is public. Even loading glyph data from fonts is probably not that hard. The potentially difficult parts (for me anyway) would be reimplementing all of what HarfBuzz does from scratch, and rendering font glyphs on the GPU, because I haven’t learned GPU programming.
Many programming bloggers have a tendency to want to inflate problems and tell you how it’s really complicated! This is something I absolutely want to avoid, and recommend everyone to avoid. When you put yourself in this mindset, you are mentally set a ceiling for yourself, convincing yourself that you’ve reached peak programming ability; after all, you are tackling such a complicated problem!
While this works most of the time, it breaks down if you only have one segment that’s wider than the line width. In general we will consider this a problem of scrolling: if you can scroll horizontally then problem solved. But it precludes other possible solutions, like hyphenation.
I want to eventually support rendering the same way in ebitengine, as I have ideas for a game-like application where I need to be able to render Arabic text.
Another compounding factor is that the Go runtime takes liberty to move memory around during GC cycles. This might make things better, or it might make them worse; I don’t know, because it’s completely outside of our control.
It’s worth noting that unless there’s an animation on the screen or UI interactions, Gioui does not force you to recompute the UI 60 times per second. Most of the time, when the screen is idle, there’s no computation taking place.
Casey also did a lecture on caching on TwitchTV, but he didn’t endup uploading it to YouTube, so I have nothing to link to. The point of the lecture was that caching is actually not the hardest problem in computer sciense, instead, it’s either trivially easy or practically impossible. If the output is always the same given some input, then caching is trivial. If the output does not depend on just the input, then it’s impossible to cache.