
Indexing/Querying strategy with BoltDB
In the previous article, I discussed reasons for moving away from SQL based relational databases (including SQLite) and pursuing a simpler strategy of a binary key-value storage system based on B-Trees. I’m currently using BoltDB for this purpose, because it’s written in pure Go, and I’m currently working in Go. If I was working in C/Odin/Zig, I would probably be using LMDB.
I talked about how I’m using it for data persistence, and explained the serialization scheme I’m using. Here it is, in case you missed it:
Data storage and retrieval from first principles

The other day I put out a small Twitter thread saying: SQLite is cool but ultimately dealing with SQL is a headache in everything but the most basic scenarios I’m not the first person to ever question the need for SQL databases. In fact, NoSQL is very big and used commonly by the web industry. The web industry went with NoSQL largely to solve performance…
In this part, I want to talk about indexing/querying for data.
Explicitness
I mentioned in my previous article that the only advantage I can think of for relational databases is that they enable automatic indexing of data. You just tell it “I want to use this column as an index” and you should get (in theory!) an acceleration structure that is maintained on your behalf by the database engine. Everytime you update a row in the table, the indicies are automatically updated.
The index should allow fast querying of data based on some property. You can tell the database: I want a list of rows where this column has this value, and the database engine should be able to retrive it for you quickly without having to go through the entire table.
Now, this is a very common type of “query” that we should want to support. I want my system to have this capability: given a specific query term, find all object ids that match.
Now, since the underlying storage system has no concept of indecies, we have to be explicit about the indexing process. Everytime we store a new version of some object, we also have to explicitly update the relevant indecies for it.
The caller is responsible for indexing data.
The caller is also responsible for using the index. There is not an “engine” that will parse a generic query and figure out which index to use. The index is a thing that you use directly to retrive data that match a certain term.
It’s similar to a hashmap that you would keep around to quickly get data by a lookup key. You don’t say “hey computer, get me this object, find the fastest you to do it yourself”. Instead you actually write the code yourself to get the object from the hashmap:
object := myMap[myLookupKey]Similarly, the way to use this index is not by saying “hey database, find me an object using this query”. Instead you directly use the index object:
myIndex.IterateTerm(term, /* .... will explain later .... */)Now, having to be explicit about it may seem like a disadvantage, but, if you we look at “modern” web development practice, we find that most development teams do exactly this: they have explicit indicies / acceleration structures that they manage themselves (manually), usually in terms of (distributed) Redis and ElasticSearch engines. I’ve seen such indexing strategies run awry with RAM or Disk space usage blowing up because of subtle difficulties in managing them correctly.
We can do better.
We can automate the “hard” part about managing the indecies so that you don’t have to worry about disk/ram utilization blowing up.
We get to keep all the architectural benefits of using a single file database.
Requirements
The reason I want to “index” data is that I want to execute certain types of queries on the data without going over the entire dataset every single time.
In generic terms, we want to support queries of the form: “I want to load a list of X objects that satisfy condition Y and be sorted by the potentially complex heuristic Z”.
We can generally reason about two types of conditions:
Conditions that naturally arise out of relations to other objects. For example, I’m on the page showing object X and I want a list of objects Y that are related to X in some way. This is what “relational” databases are all about.
Conditions explicitly triggered by user action, such as typing a search term in a text box to look for items satisfying the query.
The conditions that arise naturally in relation to other objects are the easiest to handle. The conditions that are explicitly triggered by user-input can be more difficult, depending on the particulars of the condition. For the time being, I’m not implementing a “full-text” index; that would be a future project.
From a programming point of view, what I want is a way to “replicate” what a relational database does automatically:
Update “Terms” that point to a specific object whenever the content of that object is updated.
Queries all objects that are referenced by a specific “Term”.
I’m using the word “Target” to describe the id of an object that a “Term” maps to.
This means the “index” is a bidirectional multi-map. We have a “Target” that has multiple “Terms” refer to it, and each of these “Term”s can potentially refer to many other “Target”s.
Basic Idea
Now, since we have a B-Tree, we can easily group a term with a list of its targets by just building the keys such that they contain the term first then the target. Then we iterate on the keys, starting from the first one that starts with our term.
Each key is basically [term, target] with a special prefix byte.

Because the B-Tree entries are sorted by the byte order of the keys, this arrangement guarantees that all targets related to a term are going to be grouped together: we can quickly jump to the first entry, and we can iterate over them linearly; no jumping around.
Our code can be something like this:
myIndex.IterateTerm(func(targetId int) bool {
var target Target
if myBucket.Read(targetId, &target) {
// .. read successful .. do something with `target`
}
return true // continue iteration
})Since we need to maintain a bidirectional mapping, we also need a way to iterate by target, so we have another set of keys where the target comes first, followed by the term, prefixed by a different special byte value.

Now, updating the terms that refer to a target is easy. The new terms will be provided by the caller. The existing terms can be easily retrived from the index. We figure out which terms need to be added and which need to be removed: for each term we remove, we remove both the [term, target] and the [target, term] pairs. For each pair we add, we add both.
This is the key that makes it possible to maintain the mappings without the index size blowing up.
Now, this also means that updating target terms might not be that cheap; this is the price we have to pay.
In the use case I have, this is an acceptable price, because more often than not:
A “target” has very few terms.
The “term” changes are not frequent.
This is the basic idea, and it sort of works .. until you want to sort the targets by some criterion and only pick the top N matches (for small values of N, e.g. N=20). Now you have to do a lot of extra work:
Load all the targets referred to by a term
Load their associated objects
Sort them by whatever arbitrary criteria you have
Pick the top N from the list and throw away the rest
This is too much work, and a lot of the data processed will be thrown away;.
What if instead, we associate some kind of weight or priority value to each [term, target] pairing? Then we don’t have to load all the target objects and run a custom sort on them: we know the sorting criteria right then and there.
What’s more, we can arrange the keys so that things are automatically sorted.
We add one small tweak to our scheme: instead of building keys as [term, target], we build them as [term, priority, target]. This will force the target list to be pre-sorted by the given priority.
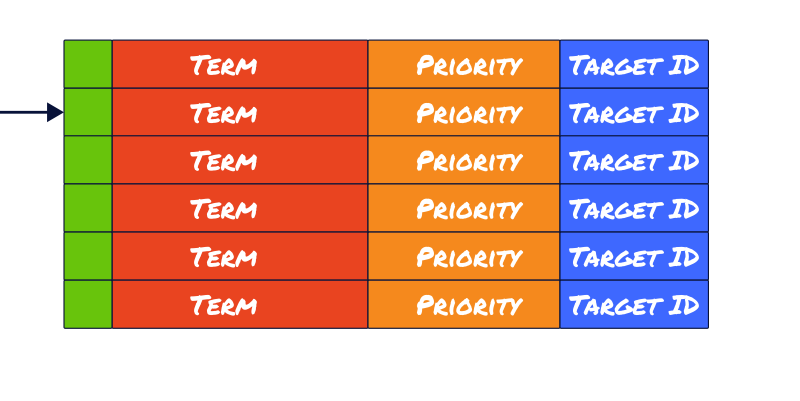
Now, the tricky part is converting a potentially complex sorting heuristic to a single number. This is only going to be a problem for the caller though; for the database engine, it’s very easy to manage.
We also update the [target, term] entries so that they indicate the priority. We don’t need terms to be sorted by priority though, so I just put the priority in the ‘value’ portion of the key => value pairing.

Now, when we update all the terms for a target, we have to take priority into account: if the new priority is different from the old one, we must delete the old pair and insert a new pair.
Now, another thing we would want to do is keep count of how many targets there are for a certain term, so that we can enable pagination easily, without slowing down our queries. Instead of iterating over all the targets for a term in order to count them, it would be must faster to just have a count pre-computed.

Maintaining the count is actually simple: since we only add/remove [term, target] pairs when we set the target terms, and since we have to keep track of which terms to add and which terms to remove, we know exactly which terms need their counts to be update. Everytime we remove a term from a target, we decrement its count, and everytime we add a new term for a target, we increment its count.
Another idea for pagination is to return an ascii encoding of the bytes that represent [term, priority, target] that would be at the start of the next page (and I mean return them all the down to the client side JS/TS code). This way, when you need to load more data, you wouldn’t need to first skip N entries in the index: you can jump straight to the start of the next page.
Computing Priorities
Now the “complicated” bit in this scheme is computing the priorities.
To give you some context, the API for setting/updating the target terms looks sort of like this:
SetTargetTerms(index *Index, target Target, terms []Term, priorities []Priority) Another complicating factor is that when you decide the priority for a [target, term] entry, you only have one target to “measure” the priority for, but this priority will determine the rank for this target in the context of all other targets referenced by this term. Your priority computation scheme should be very fast yet also robust. It should work properly without needing to “fetch” any other object in the database for comparing it with your target.
Now, it’s also important to remember that it’s totally acceptable for many objects to share an indentical priority level. There’s absolutely nothing wrong with that. They will just end up being sorted naturally by the byte order of the object id that you use to encode the ‘Target’.
It’s also worth noting that while computing a priority might be a bit of extra work, it pays dividends in terms of performance and flexibility.
Performance
Finding the object ids that match a term takes mere microseconds. I’m talking about something like 20µs. Experienced programmers might say this is actually slow. It might be, and I haven’t profiled it, but it’s so wildly faster than anything else I’ve gotten from other systems, that I’m satisfied with it.
Now, of course, this just for finding the ids of the objects that match the term. You still need to load these objects, and that takes a bit more time. But again, it’s so wildly faster than anything I’ve seen anywhere else, that it doesn’t bother me. Fully servicing a client side request could take anywhere from 100µs if the data is in RAM, all the way up to 10000µs (aka 10ms) if the data is in disk. For now, I’m satisfied with this. There’s a kind of “antifragile” property to this: the more frequently an item is accessed, the smaller the latency it is to fetch it, because everything will be hot in the cache.
On Linux, a memory mapped file can pre-populated into memory on load time, making this problem largly insignificant, except for cases where index data vastly exceed RAM size.
This is not a problem I’ve seen in any company I’ve worked with. Instead, I see the systems they use struggle with just 6GB of data, despite renting the beefiest, most expensive database server from their cloud provider.
Flexibility
You can index your data by anything you want. You’re not restricted to using only a column (or a combination thereof). You can extract some metadata about the object and use it for indexing it.
Let’s say you have micro blogging service where post content that contains hashtags and you want hashtags to link to a search page that loads all recent posts that contain the hashtag. It’s very easy to extract the hashtags from the post content, and it’s easy to update an index with these tags as the terms and the post id as the target.
It’s also easy to lower the rank of posts that just spam hashtags. Just include the number of hashtags in the post in the priority computation scheme. You can also include other things, like the frequency of posts. Maybe the more frequently the user posts, the less priority their posts get in the hashtag list. You can also decrease their priority if they have just signed up and don’t have a profile picture or haven’t confirmed their mail address or phone number. There’s no practical limit to how you can improve the relevance of search results by criteria like this.
If you have some kind of a machine learning model that can extract “topics” from post content, you can also use that and map this post to the set of topics applicable to it.
You can have another index that maps user mentions to posts, and you can lower the priority of mentions where the poster does not follow the mentioned user, etc.
Conclusion
As I’ve said many times before, I’m just experimenting with these ideas and sharing my findings in public. I’m always open to better ideas, and always interested in experimenting with new ways to improve the latency and throughoput even further.
I’m personally quite satisfied with what I have so far.
Compared to SQL based relational databases:
We have eliminated a lot of “waste”: loading objects no longer involves parsing a textual query language or running a virtual machine to excute the byte code generated from it.
We have more control over the “costs” associated with indexing data. We know exactly what’s happening when we index data. There’s no “magic”, “guessing” or “hoping”.
We have more flexibility about how to rank objects that match a query and returning more relevant results to the user.
We retain the architectural advantages of having a single file database engine that is embedded as a library in our program (as opposed to having an external server we connect to).
Full-text searching remains an open question that I will hopefully begin to tackle within the year. If and when I come up with a solution for it, I’ll be sharing it in public just like I’m doing now.
Until then, happy programming.