
Data storage and retrieval from first principles
Rethinking the basics of web development
The other day I put out a small Twitter thread saying:
SQLite is cool but ultimately dealing with SQL is a headache in everything but the most basic scenarios
I’m not the first person to ever question the need for SQL databases. In fact, NoSQL1 is very big and used commonly by the web industry. The web industry went with NoSQL largely to solve performance problems with relational databases. And while I care about performance alot, that’s not the only reaason I’m exploring this question.
I have a deep rooted sense that a lot of what people do in web development is insane. Given the problems we want to solve, the steps people go through to solve these problem involve a lot of working around sub-problems that don’t need to exist.
In the case of using SQL databases: I mostly just want a way to persist data,2 but I find myself writing SQL queries, and it feels like what I’m doing is just some irrational ritual that has nothing to do with the goal I’m actually trying to achieve.
I want to think about the problem space from first principles: What are we trying to actually achieve? What are the tools available to us? What is the most reasonable solution we can find?
Why SQL databases became ubiquitous
Dynamic, interpreted languages are almost not good at anything except glue coding. Despite this, people in the early days of the web really wanted to implement websites in these languages. But you obviously can’t implement an http server or a data presistence system in these languages, so what people did was use a web server written in C (Apache) and a database engine written in C (MySql) and put their scripts (php/perl/python) in the middle: the Apache server had some plugin(s) that could interpret the scripting language, it would pass it information about the incoming http request, and it would return the output from these scripts as the response. These scripts would connect to a MySQL server and send it plain text SQL queries to store, retrieve, and query data.
It is my position that this approach is bad, for many reasons.
For one, we should write the whole system in the same language, where the http server and the data persistence engine are just libraries you embed into the final program.
At the moment, I’m using the Go language, which has a builtin implementation of an http(s) server, and many publicly available open source libraries for doing data persistence.
SQLite is one such library: it lets you program using the typical SQL-based strategy for data persistence. While it’s actually written in C, there are ways to embed it in a Go program, so in general it’s a much better approach to programming a website than connecting to a MySQL database from a php script.
But as I alluded to in the beginning, the problem is with the concept of SQL itself.
Problems of SQL databases
1) Intermediate query langauge
With SQL based databases, all of your data storage/retrieval/querying operations have to go through an intermediate text-based language. You must construct a query string and pass it to the SQL engine. The SQL engine will then parse it and convert it to some sort of bytecode that it then executes.
Why go through all this? Why not just write the actual code directly? 99% of the time, the thing you actually want is just to load data from disk. All the other stuf is not needed.
Consider something like
select * from my_table where id = 100This will go through the parse/bytecode/execute process and ends up giving us an abstract “row” with data organized by column that we then have to read into an application level object.
Wouldn’t it be better if we could just write something like:
var obj MyObjectType
LoadData("my_table", 100, &obj)This would be less work for the machine, and less code for us to write.
We will need to write the code to serialize and deserialize the object to/from a byte buffer, but I’d argue it’s still simpler than dealing with SQL, and even more robust, as we will see below.
Important note: when I use SQLite, I do actually have generated code that does look more or less like the above function. But I’m not talking about having a higher level API on top of the SQL query.
I’m saying that a function like `LoadData` just loads a byte buffer from a specific location on disk: it doesn’t parse a query language, nor does it run bytecode in a virtual machine. It just loads data from disk. It still has to do some work to figure out where that data is, but it doesn’t perform any of the other needless busy work; all of that is just waste.
Of course, if having consistency and transactions is one of your requirements, then the `LoadData` function can be implemented with these goals in mind; but it doesn’t need to parse a textual language or run a bytecode virtual machine. It mostly just needs to traverse some efficient data structure on disk to find the data you are requesting.
2) Fragmentation of data
In a relational database, data needs to be normalized (and thus fragmented) across multiples tables and rows, relating to each other via foreign keys.
This is done regardless of the statistically common access patterns in your application.
Say you have some object A that refers to a list of objects of type B. In your application code, you would have a field in A that refers to a list of items of type B. In the database however, A and B live in different tables. The items in B have a reference back to the item in A. Furthermore, the items in B that belong A might be placed in different rows in the table.
You have to write the code that loads items from both A and B then reassembles them into the application level representation of the object (aka object-relational mapping).
You might have the code generated by machine, but it’s still extra code that needs to exist to support this use case.
The machine has to do more work to execute this code, and to fetch all the different pieces of data from different locations on disk.

What if all the data for each item in A (including the list of B items) were instead just one byte buffer?
Then we could read all of it at once, so that’s less work for the machine, and less code for us to write.
We would not need specialized code to reconstruct the application objects from the database tables: we would just have code to serialize and deserialize applications objects directly to and from a byte buffer.
Notice by the way that I mentioned “statistically common access patterns in your application.” Sometimes we do need data to be stored in different locations.
For example, you might want to separate the item summary from the item details, as we're likely to have many item summaries on the same page, but the item details has its own page for each individual item.
Since the item details has much more data than the item summaries, we prefer if we didn’t have to load 20 item details when we just want to display a page with a list of 20 item summaries.
This is what I mean by the statistically common access patterns. This is an important idea I learned from Mike Acton’s programming talks.
Relational databases force us to spread out the data regardless of whether the application would prefer them to be so or not.
3) Migrations
Changes to tables/schema over time require migrations, and these migrations need to be managed. It’s a constraint you have to always keep in mind, and it limits what you can or can’t do. It adds mental overhead, and introduces a possible source for data corruption.
You might think this is part of the essential complexity of the problem space, but you would be mistaken. The vast majority of migrations are not an essential part of the problem space of “I want to be able to persist data for later retrival”. We’ll introduce a simple method that almost removes this problem entirely: versioning. But let’s not get ahead of ourselves here.
This problem is not limited to SQL databases. They could also be present in “json” based document stores, at least if all you do is naive json serialization and deserialization.
Now, the upside of relational database engines is that they make indexing trivial; you just declare what you want to index and the database engine will manage the indecies for you: inserting, updating, and deleting data as needed.
Is this tradeoff worth it? I personally think it’s not.
What do we actually need?
If I think about what are the actual capabilities I need from a database, they are:
Store objects and have them be addressable by some unique id.
Have the code for saving/loading objects be simple and robust.
Create unique indecies.
Create indecies that maps a key to a (potentially large) list of object ids and then be able to load a portion of these objects quickly.
BoltDB
In trying to achieve these goals I’m trying to use the boltdb package3. It’s an open source library of a B-Tree based key-value storage engine.
The main features are:
Buckets hierarchy, where each bucket is a B-Tree of key→value items:
Both the key and the value are just byte buffers.
You can iterate those items in order.
You can just load a value associated with a key.
Write transactions are serialized, meaning there’s only one active write transaction at a time.
This means we can:
Store objects by a uuid, where the key is the uuid, the value is a serialization of the object (which I will cover in the next section).
We can store each type of object in its own bucket.
We can “chunk” complex objects to multiple parts, where each part lives in its own bucket, but shares the same uuid.
Create unique indecies where the key is the index and the value is the uuid of the target object.
Each such index has its own bucket
Uniqueness is easy to guarantee, because we're guaranteed one write transaction at a time.4
Create one-to-many indecies using buckets, where the key is somehow encoded in the bucket name, and the uuids of objects that match are the keys in the bucket (the values are kept empty).
Since the keys are stored in B-Tree, the list can be arbitrarily large, and we can add/remove keys arbitrarily with very little overhead.
The potential downside is that we have to manage indexing the data ourselves since boltdb’s API is relatively low level and has no concept of “object” vs “index”: it’s just buckets with key→value mappings.
Object Serialization
People coming from a web background like myself have a very weird idea about serialization: we think it means “json”, or that “json” is the only sensible format. But there’s another way, that seems more sensible, and is used in (at least some) systems and game programming circles: binary serailization where you just dump all the fields of a struct into a buffer, one by one. When you deserialize, you read the fields in the same order.
For integers, there’s a way to use a small number of bytes for small values (the various XxxxVarint functions from the encoding/binary package in the standard Go library come in very handy here). For strings, we write the length first followed by a bytes dump. Same for arrays/slices.
We don’t mark the boundaries of fields or values, nor do we encode their type. There’s hardly any metadata to speak of.
Instead, to make the operation more reliable and robust, we use two techniques:
Writing out a version number. The version determines how to read/write the data.
Use the exact same code to read and write the data, and have a mode flag that controls the behavior.
It might seem like lacking metadata makes things brittle, but actually the version based scheme is more robust than json (or other schemes that encode the data type, such as msgpack). Versioning allows for changing the object layout without running an explicit migration process on the database. We’ll expand on this in the next section.
Here’s a simple visualization of how we might serialize an instance of some imaginary object with int, string, and bool fields.
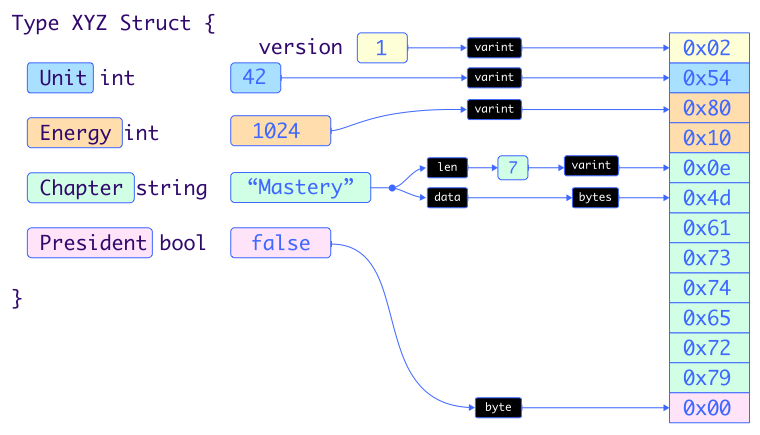
You may notice a few things:
The serialization takes exactly 13 bytes.
Due to the
varintencoding scheme, the number of bytes used to serialize integers depends on the value of the integer, and even when using just one byte, the hex value does not match what you would expect.There is no metadata other than the version number. Someone looking at this byte buffer without context will have no idea how to decipher it.
This is easy to scale to large and more complicated objects. Say you want to serialize a list of 10 XYZ items that are inside some other struct KLMN. Part of the KLMN serialization is you write “10” to indicate 10 items, then you write the 10 items to the buffer one by one.
Let’s look at a high level code example of a serialization function:
type XYZ struct {
Unit int
Energy int
Chapter string
President bool
}
func SerializeXYZ(xyz *XYZ, buf *store.Buffer) {
var version = 1
store.Int(&version, buf)
switch version {
case 1:
store.Int(&xyz.Unit, buf)
store.Int(&xyz.Energy, buf)
store.String(&xyz.Chapter, buf)
store.Bool(&xyz.President, buf)
default:
buf.Error = true
}
}I made up a convention of defining serialization functions so the first parameter is a pointer to the thing and the second item is the serialization buffer.
Note that this function does both serialization AND deserialization. Since the code is the same, we are guaranteed that reads and writes happen in the same order.
The buffer has a mode flag that determines whether we’re in serialization or deserialization mode. Most high-level serialzation functions don’t have to check this flag, but the lower level functions do actually check it. For example, here’s the function from the store package that reads/writes int64 values using varint encoding
func VInt64(n *int64, buf *Buffer) {
switch buf.Mode {
case Serialize:
buf.Data = binary.AppendVarint(buf.Data, *n)
case Deserialize:
var err error
*n, err = binary.ReadVarint(buf)
if err != nil {
buf.Error = true
}
}
}
The store package implements the serialization buffer and the serialization functions for the basic types. These functions form the building blocks in terms of which object serialization functions can be constructed.
The store package also define helpers to prepare the buffer in read or write mode. store.NewWriter() prepares in in write mode, while store.NewReader(byteSlice) takes a byte slice and prepares the buffer in read mode.
Here’s a code example of using that SerializeXYZ function defined above to serialize an object to a byte buffer, printing the buffer data to the screen in hex format, then reading the buffer back into a new object and printing it to make sure we are able to get back the original values.
func main() {
var data []byte
// Serialization Example
{
fmt.Println("Serialization")
fmt.Println("==================")
var item XYZ
item.Unit = 42
item.Energy = 1024
item.Chapter = "Mastery"
item.President = false
var buffer = store.NewWriter()
SerializeXYZ(&item, buffer)
fmt.Printf("Item: %#v\n", item)
fmt.Printf("Data: %# 02x", buffer.Data)
fmt.Println()
fmt.Println()
data = buffer.Data
}
// Deserialization Example
{
fmt.Println("Deserialization")
fmt.Println("==================")
var item XYZ
var buffer = store.NewReader(data)
SerializeXYZ(&item, buffer)
fmt.Printf("Item: %#v\n", item)
}
}And this is the output:
Serialization
==================
Item: main.XYZ{Unit:42, Energy:1024, Chapter:"Mastery", President:false}
Data: 0x02 0x54 0x80 0x10 0x0e 0x4d 0x61 0x73 0x74 0x65 0x72 0x79 0x00
Deserialization
==================
Item: main.XYZ{Unit:42, Energy:1024, Chapter:"Mastery", President:false}Notice how the item we wrote and the item we read live in difference isolated scopes, thus have no access to each other, but we were able to read back all the data correctly, indicating that this the serialization scheme probably works.
Versioning
I briefly mentioned above that versioning makes this scheme robust and allows us to change object layout without migrating the database.
I will try to explain how this works by giving a concrete example, basing it on the sample code above.
I’ll start by modifying the above code so that the serialization buffer is written to disk:
os.WriteFile("data/xyz_v1.bin", data, 0644)I’ll execute it once to make sure the buffer is saved to said file, then I’ll update the code by adding a new field, removing another one, and updating the serialize function.
I’ll do it as if it was a migration: I will remove the “Energy” field and replace it with “Price”, where the price is energy * unit. These are completely ficticious concepts and are not based on anything in real life, despite the familiar nouns.
Normally, this is the kind of thing you’ll need to run a migration on a database to achieve: add a new column, populate it with correct value, remove old column.
But here, all we do is change the code: update the struct definition and the serialize function. In the sample code below, I highlight the important lines by bold-formatting them:
type XYZ struct {
Unit int
Price int
Chapter string
President bool
}
func SerializeXYZ(xyz *XYZ, buf *store.Buffer) {
var version = 2
store.Int(&version, buf)
switch version {
case 1:
store.Int(&xyz.Unit, buf)
var energy int // Field that used to exist in previous version
store.Int(&energy, buf)
store.String(&xyz.Chapter, buf)
store.Bool(&xyz.President, buf)
// In the new version, price is energy * unit
xyz.Price = energy * xyz.Unit
case 2:
store.Int(&xyz.Unit, buf)
store.Int(&xyz.Price, buf)
store.String(&xyz.Chapter, buf)
store.Bool(&xyz.President, buf)
default:
buf.Error = true
}
}Notice we start by setting version to 2: this is the new (and highest) version number, which is what we would like to write to the serialization buffer.
However, recall that when we call store.Int(&version, buf), what happens depends on the mode of the buffer.
If we are in deserialize mode, this will read a number from the buffer instead of writing to it, so now the variable version should corrspond to the version stored in the buffer for the object.
Then we have two code branches: one for each version.
Notice how in the branch for version == 1, we create a new temporary local variable to read the ‘Energy’ value into. Also notice how at the end we set the price value by a computation based on the deserialized values.
This piece of code contains the logic that otherwise would to be encapsulated in an SQL query and applied during a migration process that needs to be executed on the entire database before deploying the new version of the application.
With versioning, there’s no need for such process. The logic is encapsulated in a little piece of code that executes only as needed (on demand) when we load data serialized in the previous version.
We don’t need to “migrate” the database; we just deploy the new version of the application and it knows how to read the old data.
To make sure this works, I executed the following piece of code to load the previously serialized data:
data, err := os.ReadFile("data/xyz_v1.bin")
if err != nil {
log.Panicln(err)
}
fmt.Println("Deserialization")
fmt.Println("==================")
var item XYZ
var buffer = store.NewReader(data)
SerializeXYZ(&item, buffer)
fmt.Printf("Item: %#v\n", item)And the output says:
Deserialization
==================
Item: main.XYZ{Unit:42, Price:43008, Chapter:"Mastery", President:false}We can verify that 1024 * 42 = 43008, so it appears that this this scheme is working as intended!
Topics for further investigation
Indexing data and doing advanced queries
I have already described a simple scheme for indexing data by utilizing the buckets feature of boltdb. To be honest though I haven’t used it extensively yet so I will come back to this topic in a later article once I have more experience with this subject.
The same applies to advanced queries outside relational databases. I have some rough ideas but I will come back to this topic at a later time.
Until then, happy coding.
Indexing/Querying strategy with BoltDB

In the previous article, I discussed reasons for moving away from SQL based relational databases (including SQLite) and pursuing a simpler strategy of a binary key-value storage system based on B-Trees. I’m currently using BoltDB for this purpose, because it’s written in pure Go, and I’m currently working in Go. If I was working in C/Odin/Zig, I would p…
I remember experimenting with CouchDB as far back as 2013, and then ultimately deciding to go back to SQL because things were simpler that way (I was programming in Python back then, so give me a break).
There are two reasons for wanting to persist data:
1) So that I don’t have to load all of it into memory
2) So that I can shutdown and restart the program and still have the same data.
Obviously, by using an existing package, we’re not really thinking from “first principles”. We are however, pretty close: key-value mapping is about as low-level as you can get, and a B-Tree is probably the core building block that we will have to use anyway. I didn’t choose this package arbitrarily, I chose it because it does the heavy lifting of the most complex/sensitive/brittle parts of the system.
This works great when we’re working on a single machine. If we decide to scale horizontally and distribute the data across multiple machines, we need to handle this problem differently: we have to allow for the possibility that another instance is trying to write a different value to the same key at the same time, and have a mechanism for ordering these requests and resolving their conflicts by failing one of them.